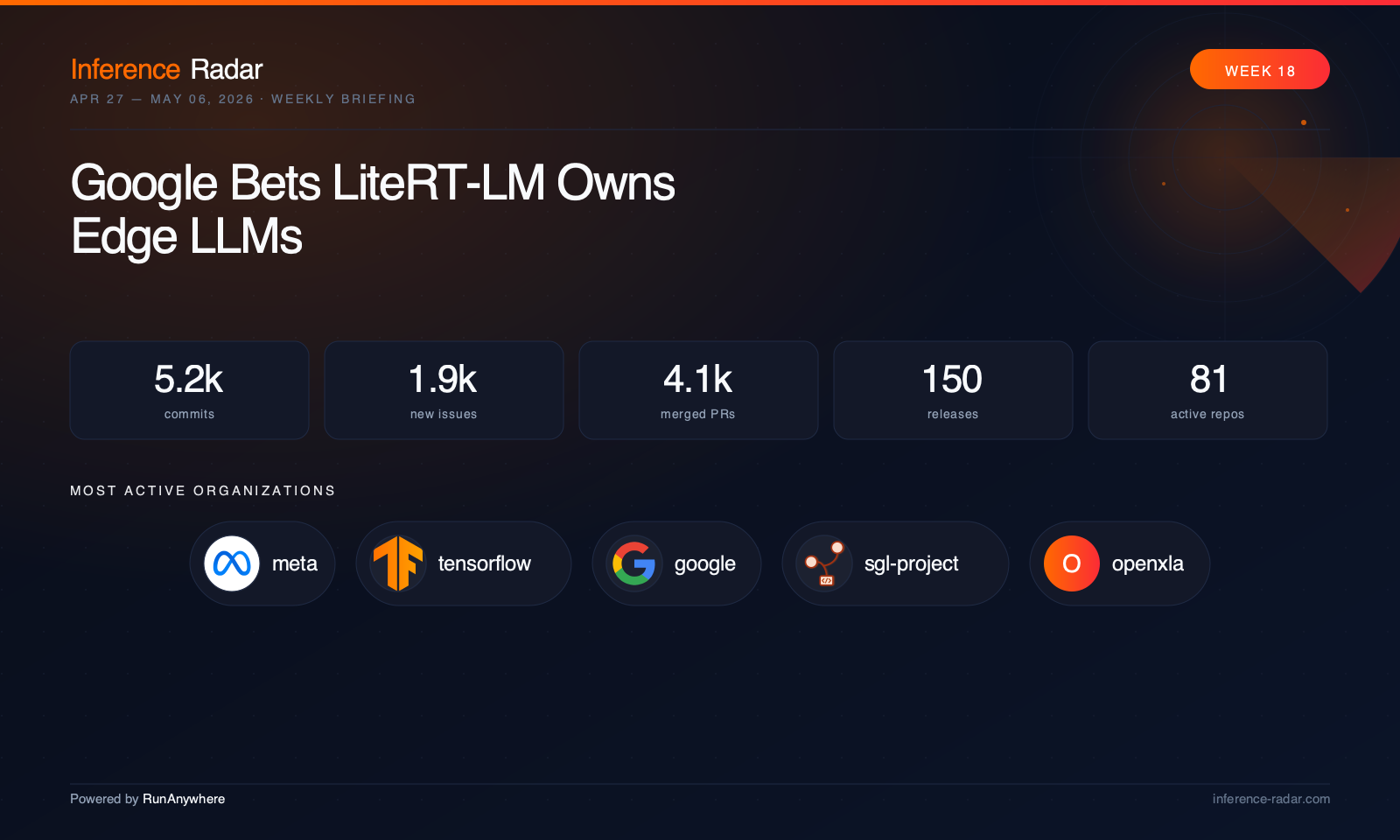

TL;DR
- DeepSeek V4 became the week’s integration test: vLLM, SGLang, TensorRT-LLM, ktransformers, oMLX, and OpenVINO GenAI all spent the week enabling or stabilizing DeepSeek V4-class serving paths, making model bring-up speed the new benchmark for inference platforms.1
- Google made LiteRT-LM the center of gravity for edge LLMs: LiteRT, LiteRT-LM, and MediaPipe now point in one direction — mobile LLM inference is consolidating around a dedicated runtime rather than living as a sidecar feature.7
- Apple-local inference kept moving up the stack: Ollama, MLX, mlx-vlm, oMLX, and vllm-mlx all pushed beyond raw execution into speculative decoding, multimodal serving, qualification tooling, and app-facing APIs.5
- Serving projects are differentiating on operations, not just kernels: Ray Serve, ai-dynamo, Triton Inference Server, BentoML, and LiteLLM all focused on rollout safety, cache correctness, metrics integrity, auth, and multi-replica behavior.14
- Gemma 4 is now a cross-stack forcing function: llama.cpp, Ollama, mlx-vlm, OpenVINO GenAI, LiteRT samples, and TensorRT-LLM all used Gemma 4 support to stress-test speculative decoding, multimodal handling, and sliding-window attention semantics.3
This Week in Inference
The market briefing for this issue came in with a hole in the middle: the external search pipeline failed, so there’s no responsible way to claim week-specific funding rounds, hardware launches, or model announcements beyond what the repos themselves clearly show. But the repo data is strong enough to reveal the real story anyway: the open-source inference ecosystem is converging into a single stack, and the boundaries between cloud serving, local runtimes, and edge deployment are getting thinner every week. You can see it in the same model families showing up everywhere, the same OpenAI- and Anthropic-shaped APIs appearing across projects, and the same engineering problems — cache movement, speculative decoding, multimodal routing, quantization portability — repeating from datacenter engines down to browser and mobile runtimes.
The clearest example this week was DeepSeek V4. It wasn’t just “supported” by one flagship server; it became a cross-ecosystem integration event. vLLM pushed core and ROCm support, SGLang kept tightening large-scale serving around new model paths, TensorRT-LLM advanced multimodal and sparse attention plumbing, ktransformers shipped a hybrid CPU/GPU path for DeepSeek V4 Flash, oMLX made it a first-class Apple Silicon target, and OpenVINO GenAI added both baseline and MoE support.1 That matters because model bring-up speed is now a platform capability. If your runtime can’t absorb a new architecture quickly, you’re not just missing a benchmark cycle — you’re falling out of the deployment path.
The second big pattern is that edge inference is professionalizing. Google’s LiteRT, LiteRT-LM, and MediaPipe changes amount to a strategic reorg in public: mobile LLM inference is no longer a side feature, it’s a dedicated runtime lane.7 On Apple hardware, Ollama, MLX, mlx-vlm, oMLX, and vllm-mlx are all climbing the stack from “can run a model” to “can serve, benchmark, qualify, and integrate it into apps.” In the browser, WebLLM added Origin Private File System persistence, which sounds small until you remember that browser-local model storage is the difference between a demo and a usable product.5
The third pattern is operational maturity. The most important serving work this week wasn’t a flashy kernel chart; it was Ray Serve adding rollout controls and Kubernetes resizing, ai-dynamo broadening its backend surface and KV-routing machinery, Triton Inference Server tightening request validation and packaging correctness, BentoML fixing a subtle multiprocess metrics bug, and LiteLLM hardening budget enforcement, cache isolation, and proxy security.14 That’s what a maturing market looks like: less obsession with single-stream speed, more attention to what breaks when inference becomes a real service.
Top Stories
vLLM turns DeepSeek V4 support into a platform race vLLM spent the week doing more than adding another model family: it used DeepSeek V4 to push on the hard parts of modern serving, from ROCm enablement to KV transfer, speculative decoding, and backend-specific correctness.1 The result is that vLLM is increasingly less “an OpenAI-compatible server” and more the reference implementation for how quickly a datacenter inference stack can absorb a new architecture under real production constraints. Just as important, the work spilled into the plugin ecosystem, with vllm-gaudi chasing upstream compatibility and simplifying its own execution model.22 That’s a sign of maturity: when the core project moves fast enough that downstream hardware plugins must reorganize around it, the center of gravity is obvious.
Google consolidates edge LLM inference around LiteRT-LM The most strategic move of the week may have been Google’s quiet product-line clarification across LiteRT, LiteRT-LM, and MediaPipe.7 MediaPipe de-emphasized its public mobile LLM inference engine while LiteRT and LiteRT-LM expanded multimodal support, packaging, delegate controls, and platform coverage, making the intended architecture much clearer. This matters because edge AI has suffered from too many overlapping abstractions. Google now appears to be saying that on-device LLM inference deserves its own runtime and tooling path, not a generic media framework bolt-on. If that sticks, LiteRT-LM becomes one of the most important repos to watch in mobile inference.
Ollama is becoming an app platform, not just a local model runner Ollama had a week that looked messy on the surface — rapid releases, regressions, and lots of issue traffic — but the direction is unmistakable.10 Claude Desktop integration, launch-time caching, model recommendation plumbing, and deeper MLX work around Gemma 4 speculative decoding all point to the same shift: Ollama is moving from “CLI for local models” toward a local AI application substrate. That’s strategically important because local inference distribution is no longer just about model files and tokens per second. It’s about integrations, app lifecycle, account-aware gating, and runtime behavior on real desktops. Ollama’s issue volume shows the pain of that transition, but also confirms where the project is headed.
SGLang pushes the serving frontier into disaggregation and diffusion SGLang had one of the heaviest engineering weeks in the ecosystem, and the interesting part wasn’t just the platform baseline move.2 The project kept pushing decode-side radix cache reuse for disaggregated serving, elastic expert parallel recovery, and dynamic batching for diffusion workloads — exactly the kinds of features that matter when serving gets more heterogeneous and more multimodal. That puts SGLang in a distinct lane. Where some engines still compete on classic LLM throughput, SGLang is increasingly optimizing for the next serving topology: split prefill/decode, large-scale MoE, and mixed text-image-video generation under one scheduler.
OpenVINO shows why “edge” now includes serious model-serving work
OpenVINO, OpenVINO GenAI, and NNCF together had one of the most complete full-stack weeks in the ecosystem.6 Gemma 4, Gemma 4 MoE, Qwen 3.5 VLM, SDPA fixes, NPU/GPU runtime work, generation controls like min_p, and safer serialization/config loading all landed in parallel.
The takeaway is that “edge inference” no longer means toy models or stripped-down runtimes. OpenVINO is building a stack that wants to handle modern multimodal and MoE workloads with the same seriousness cloud engines bring to datacenter GPUs — just mapped onto Intel’s CPU, GPU, and NPU footprint.
Deeper Dive
Everything below is for readers who want the full picture. Feel free to scroll.
Code Changes by Category
Cloud & Datacenter Serving
The datacenter serving layer had a week defined by architecture absorption and operational hardening.
vLLM was the center of gravity.1 DeepSeek V4 support landed and then immediately expanded into AMD paths, wrapper fixes, KV-transfer optimizations, Gemma 4 MTP speculative decoding, TurboQuant broadening, and a long list of backend-specific correctness work across ROCm, CPU, XPU, and pipeline parallel scheduling. The pattern is familiar now: new model support is no longer a discrete feature, it’s a forcing function that touches every subsystem in the engine.
SGLang matched that intensity with a different emphasis.2 The project’s most important work was around disaggregated serving and large-scale resilience: decode-side radix cache reuse, elastic expert parallel recovery, cache coherence for context-parallel setups, and communication-path cleanup. It also kept pushing diffusion serving, where dynamic batching for prompt-only requests is becoming a real differentiator as text and image/video serving converge.
NVIDIA TensorRT-LLM spent the week on multimodal correctness and deployment breadth.3 Chunked prefill for interleaved video/text layouts, Gemma vision support in AutoDeploy, DFlash speculative decoding, sparse MLA work, and KV-transfer cancellation all point to the same thing: TensorRT-LLM is trying to make Blackwell-era multimodal serving feel native rather than bolted on. The repo’s issue traffic also shows the tension between raw performance and production ergonomics, especially around AutoDeploy and large-model memory behavior.
Ray had one of the most practically important serving weeks.14 Kubernetes in-place pod resizing, configurable rolling update percentages, ingress routing work, and vLLM integration fixes are exactly the kind of changes that matter to operators but rarely make headlines. Ray Serve is increasingly differentiating on rollout safety and cluster behavior, not just API shape.
ai-dynamo broadened its backend surface with TokenSpeed while continuing to invest in KV routing, replay infrastructure, operator maturity, and frontend compatibility.15 The project’s roadmap discussions make clear that it sees itself as more than a thin orchestrator around other engines; it wants to become a serving control plane that can mix backends, cache tiers, and agentic workflows.
Triton Inference Server had a smaller but meaningful week: stricter request validation, correct binary wheel tagging, and a clean release-cycle transition.16 The open S3 SIGPIPE crash report is also a useful reminder that “boring” infrastructure bugs still matter enormously in production serving.
BentoML fixed a subtle but high-impact Prometheus multiprocess histogram bug.17 That’s the kind of issue that quietly poisons observability in production and is more important than many feature releases. It also cleaned up Dockerfile generation, reinforcing the project’s focus on deployment correctness.
LiteLLM had one of the most operationally dense weeks anywhere in the ecosystem.18 Budget pre-reservation, Redis/cache consistency, multi-replica auth behavior, and a broad security hardening sweep all landed together. LiteLLM is increasingly less about “one API for many providers” and more about being a policy and control layer for production inference traffic.
LMDeploy expanded its API surface with Anthropic-compatible endpoints and richer multimodal request handling while also pushing Blackwell-oriented MoE performance work.25 It remains one of the more underappreciated projects in the serving layer because it keeps shipping compatibility and performance work without much noise.
LocalAI deserves mention here even though it straddles local and server use cases.26 Distributed vLLM support, replica routing, model gallery performance, and new audio endpoints show it increasingly behaving like a general-purpose self-hosted inference platform rather than a simple local wrapper.
Local LLM Runtimes
The local runtime layer is moving up-stack fast.
llama.cpp had another classic high-velocity week: new model support, backend acceleration, memory estimation fixes, server hot reloads, and unsupported-architecture handling.19 The interesting part is how much of the work now looks like platform maintenance rather than pure kernel hacking. The project is still the portability king, but it’s also becoming more server-like and more multimodal.
Ollama is in transition.10 Claude Desktop integration, launch infrastructure, recommendation caching, and MLX-side Gemma 4 speculative decoding are all signs of a project trying to own the local AI app experience, not just model execution. The regressions and issue volume are real, but they’re also what happens when a runtime becomes a product platform.
text-generation-webui spent the week stabilizing its Electron desktop rollout.27 That may sound cosmetic, but it’s actually a meaningful shift: local inference UX is increasingly expected to ship as a desktop product, not a Python web app. The rapid Linux and Windows fixes show how much packaging and shell behavior now matter.
llamafile focused on GPU backend detection and Windows DLL discoverability.28 That’s exactly the right kind of work for its niche: making “single-file local inference” survive real-world system weirdness. The project’s value proposition depends less on new model support than on reducing setup ambiguity.
GPT4All had no code activity, but the community discussions are revealing.29 Users increasingly want prompt-template quality, local server mode, and purpose-built models. That’s a reminder that the local runtime market is no longer just about raw capability; it’s about workflow fit.
exo kept pushing distributed local inference reliability, MLX backend architecture, and benchmarking tooling.30 The open CUDA Docker work is especially notable because it suggests EXO is trying to escape the “Apple-only curiosity” box and become a broader distributed local inference fabric.
Apple Silicon & MLX Ecosystem
This was another strong week for the Apple-local stack, but the center of gravity keeps moving from kernels to systems.
MLX itself focused on correctness and compatibility: CUTLASS half matmul behavior, safetensors support for DeepSeek-style formats, and linalg additions.11 That’s foundational work, but the more interesting action is happening in the ecosystem above it.
mlx-vlm had one of the week’s most important Apple-side updates with Gemma 4 speculative decoding and a stream of batching and server-compatibility fixes.12 It’s increasingly acting like a proper serving layer for multimodal MLX workloads, not just a model runner.
mlx-audio and mlx-audio-swift kept broadening the audio stack with VAD, TTS model support, long-form ASR fixes, and OpenAI-compatible API behavior.31 The cross-language symmetry between Python and Swift is especially notable; it suggests a maturing on-device audio ecosystem rather than isolated experiments.
oMLX had a major systems week.5 DeepSeek V4 support, SSD/prefix cache redesign, native MTP toggles, long-context stability fixes, and Anthropic compatibility work make it one of the most ambitious Apple-native inference engines right now. It’s trying to solve the same problems as cloud servers — cache formats, tool calling, SSE behavior — on top of MLX.
vllm-mlx is also worth watching.13 Qualification tooling, cancellation, cache controls, Gemma 4 audio support, and schema/constrained decoding fixes all push it toward “operational MLX serving” rather than a compatibility layer. If that project keeps compounding, it could become the bridge between datacenter serving expectations and Apple-local deployment.
WhisperKit hitting a major SDK milestone matters because it reflects the same trend in speech: Apple-local inference is becoming product infrastructure.33 Binary packaging, Swift 6 modernization, and reusable audio components are what mature ecosystems look like.
Mobile & Edge Frameworks
The mobile and edge layer had one of its clearest strategic weeks in months.
LiteRT and LiteRT-LM are now clearly the core of Google’s edge LLM story.7 Large-model loading, multimodal parity, packaging across Windows and Linux ARM, delegate controls, and cancellation fixes all point to a runtime that expects serious deployment, not just demos.
MediaPipe effectively confirmed that shift by deprecating public mobile LLM inference artifacts in favor of LiteRT-LM while still expanding embedding support elsewhere.9 That’s a strategic simplification of the stack.
ExecuTorch had a backend-portability-heavy week.34 Arm layout refactors, MLX support for torch.roll, Qualcomm AI Engine Direct work, CUDA graph capture for MoE decode, and ongoing CoreML hardening show a project trying to be the deployment substrate for PyTorch models across very different accelerators. The code freeze for CI recovery also says something important: edge deployment frameworks are now big enough that release discipline matters as much as feature velocity.
ncnn had a quieter week, but the pnnx conversion improvements and Windows ARM build fix fit the same pattern: edge inference success depends on conversion and packaging reliability as much as on kernels.35 The open SDPA and flash-attention work suggests more aggressive transformer optimization is coming.
MNN only landed one commit, but it was strategically relevant: a Vulkan linear-attention fallback for devices without subgroup support.36 That’s exactly the kind of portability work that determines whether an edge runtime works on real hardware fleets.
sherpa-onnx had a broad release spanning Android, Flutter, iOS, HarmonyOS, Rust, Python, and Node, with new Parakeet and Nemotron support.37 Speech remains one of the most practical edge AI categories, and sherpa-onnx continues to act like a serious cross-platform deployment layer rather than a research repo.
picoLLM expanding into embeddings, vision, and OCR is another sign that edge runtimes are broadening beyond text chat.38 The on-device stack is becoming multimodal by default.
Compilers, Runtimes & Graph Engines
Compiler and graph-engine work was unusually strong this week, and it matters because inference portability still lives or dies here.
OpenXLA XLA had a huge week led by a critical ScalarConstantSinker correctness fix, plus GPU autotuning, ROCm gfx12 enablement, allocator integration, and lowering improvements.39 This is the kind of work that quietly shapes the reliability of JAX, TensorFlow, and downstream compiler stacks.
TensorFlow mirrored much of that XLA-heavy work while TFLite Micro kept reducing dependence on the monolithic TensorFlow package.40 That decoupling matters for embedded inference tooling, where install weight and maintenance burden are real blockers.
TVM had one of the most architecturally interesting weeks: FFI/runtime reorganization, Relax frontend expansion, importer correctness, and GPU/runtime fixes.42 The project’s strategic shift toward Relax is becoming more explicit, and the tvm-ffi work suggests a longer-term effort to modernize the runtime boundary.
Triton kept pushing low-precision kernel support, backend breadth, and sanitizer infrastructure.43 NVFP4 tuning, split-K matmul flexibility, AMD gfx1250 work, and a wave of correctness fixes reinforce Triton’s role as the kernel workbench for modern inference stacks.
TileLang is increasingly interesting as a compiler/runtime project to watch.44 Windows support, backend decoupling, FP4 TensorMap/TMA work, and low-bit dtype plumbing all suggest a project trying to become a serious kernel-generation layer rather than a niche experiment.
ONNX and ONNX Runtime had a notably LLM-shaped week.45 FlexAttention, attention spec cleanup, Gemma-style sliding-window discussion, CUDA attention dispatch changes, WebGPU plugin packaging, and a long list of correctness fixes show the ONNX stack adapting to modern transformer semantics rather than just preserving old interoperability.
MIGraphX also deserves attention for symbolic-shape propagation and dynamic/symbolic cleanup.47 AMD’s inference story increasingly depends on these compiler/runtime layers becoming less brittle.
Models, Quantization & Optimization
The model and quantization layer this week was less about standalone quantization papers and more about quantization becoming embedded in every runtime path.
Hugging Face Transformers added DeepSeek V4, Granite Vision, EXAONE, and more while tightening multimodal and MoE behavior.48 Diffusers expanded pipelines and fixed offload/device correctness.49 These libraries remain the upstream source of truth for model semantics, and every inference engine downstream depends on how quickly they stabilize new architectures.
Intel Neural Compressor focused on realistic validation and export interoperability.50 That’s important because quantization is increasingly a product requirement, not a benchmark trick, and validation quality matters more than another compression acronym.
NNCF worked on graph extraction correctness, noop cleanup, and safer serialized config loading.24 That’s the kind of infrastructure that makes quantization deployable in real pipelines.
ktransformers had one of the most interesting quantization weeks in the ecosystem.4 DeepSeek V4 Flash support with MXFP4 MoE, Triton fallback for consumer GPUs, and a new AVX2/AVX-VNNI RAWINT4 backend show how hybrid inference stacks are evolving: not just “GPU quantization” or “CPU quantization,” but coordinated low-bit execution across both.
ROCm AITER and ATOM kept pushing fused kernels, MoE routing, Split-K correctness, and DeepSeek V4-specific paths.51 This is where a lot of AMD’s practical inference competitiveness will be won or lost.
CTranslate2 had no merges, but the security hardening discussion around legacy checkpoint loading is worth flagging.53 As quantized and converted checkpoints proliferate, deserialization safety is becoming a bigger issue across the ecosystem.
Other Notable Changes
WebLLM adding OPFS support is more important than it looks.21 Browser-local persistence is a prerequisite for serious WebGPU inference, and the project also kept generalizing multimodal handling away from model-specific hacks.
FluidAudio, mobius, and text-processing-rs had a strong week in Apple-local speech.54 Mandarin Kokoro support, StyleTTS2 exploration, diarization improvements, and text normalization fixes show a stack moving quickly from experimentation to productization.
Osaurus kept pushing agent execution, sandboxing, provider management, and prompt inspection.57 It sits adjacent to inference rather than inside it, but it’s a useful signal of where local model runtimes are headed: toward full application harnesses, not just chat windows.
Liquid4All and related repos focused on examples, SDK cleanup, and public model/docs surfaces.58 That’s another sign of a maturing market: examples and packaging are becoming strategic assets.
Community Pulse
The loudest community signal this week was not “which project is fastest,” but “which project survives contact with users.”
vLLM and SGLang both saw heavy issue traffic around DeepSeek V4, MoE regressions, long-context behavior, and platform-specific failures.1 That’s what leadership looks like in open-source inference right now: you become the place where every new model’s edge cases get discovered first.
Ollama had a flood of issues around Claude Desktop integration and MLX regressions, but that’s also evidence of its expanding role.10 People are no longer just using Ollama to run a model; they’re trying to build workflows and app integrations on top of it.
Open WebUI had almost no landed code but enormous support load.59 That’s a useful reminder that UI and orchestration layers are now critical parts of the inference stack, and their bottlenecks are often operational rather than architectural.
llama.cpp continued to attract high-signal discussion around speculative decoding, Vulkan/Gemma vision issues, and tool-call formatting.19 The repo remains the ecosystem’s broadest compatibility surface, which means it also becomes the first place many model-format and backend mismatches show up.
On the Apple side, oMLX, mlx-vlm, and vllm-mlx all saw active discussion around MTP, batching, cache behavior, and serving semantics.5 That’s a sign Apple-local inference is no longer a novelty lane; it now has enough users to generate real operational feedback loops.
Security and safety also surfaced more than usual. LiteLLM shipped a broad hardening sweep, OpenNMT CTranslate2 discussed safer legacy checkpoint loading, Intel Neural Compressor received a serious deserialization vulnerability report, and ONNX removed insecure workflow patterns.18 As inference stacks become infrastructure, these issues stop being side notes.
Worth Watching
1. DeepSeek V4 as the new compatibility benchmark This week’s cross-repo activity suggests DeepSeek V4 is becoming the new “can your engine really handle modern inference?” test. Watch which projects move from initial support to stable long-context, multimodal, and multi-backend behavior first.
2. Gemma 4 as the speculative decoding proving ground Gemma 4 showed up across local, cloud, and edge stacks as the model family most likely to force MTP, sliding-window attention, and multimodal fixes. Expect more repos to use Gemma 4 support as a public benchmark for speculative decoding maturity.
3. LiteRT-LM’s consolidation effect Google’s stack simplification around LiteRT-LM could have second-order effects across mobile inference. If developers start treating it as the default Android-edge LLM runtime, adjacent projects will need clearer differentiation.
4. Apple-local serving is getting serious The combination of Ollama, oMLX, mlx-vlm, and vllm-mlx suggests Apple Silicon is becoming a real deployment tier, not just a developer convenience.5 Watch for more qualification, benchmarking, and API-compatibility work here.
5. Disaggregated serving is moving from concept to product Between SGLang, vLLM, ai-dynamo, and TensorRT-LLM, the prefill/decode split is no longer experimental.1 The next question is which stack makes it operationally boring.
6. Edge runtimes are becoming multimodal by default OpenVINO GenAI, LiteRT-LM, picoLLM, sherpa-onnx, and mlx-audio all point the same way: edge stacks are no longer text-only.6 That raises the bar for memory planning, operator coverage, and packaging.
Major Releases
ai-dynamo shipped two releases, with the stable cut centered on making Dynamo a more complete serving control plane and the development cut aimed at DeepSeek V4 on Blackwell. The dominant theme was broadening backend and deployment surface area while hardening KV indexing and multimodal serving. The most impactful change was the stable release’s production-grade KV indexer and expanded API compatibility. 60
Apache TVM FFI shipped a release that looks small on paper but matters strategically because it supports TVM’s ongoing runtime and FFI decoupling. The theme across Apache’s work was internal modernization: cleaner boundaries, better Python interop, and more mature container conversion behavior. The most impactful change was recursive DLPack container conversion and C++-side stream scanning in tvm-ffi. 61
Argmax shipped a milestone release by turning WhisperKit into the broader Argmax Open-Source SDK. The theme was productionization on Apple platforms: Swift 6 migration, binary distribution groundwork, and a broader audio stack that now spans transcription, speaker, TTS, and shared core components. The most impactful change was the SDK unification itself, which turns a single speech library into a reusable on-device audio platform. 62
BerriAI shipped a rapid sequence of stable, patch, RC, and dev releases for LiteLLM, all reflecting the same priority: production hardening under heavy user load. The dominant theme was budget correctness, cache consistency, and proxy security, with compatibility work across realtime and provider APIs layered on top. The most impactful change was pre-reserving spend before dispatch to close budget-enforcement race windows in multi-replica deployments. 63
Blaizzy shipped notable releases for both mlx-vlm and mlx-audio, with the week’s center of gravity clearly on Gemma 4 speculative decoding and broader audio-model support. The org’s release pattern shows a fast feedback loop around Apple-local multimodal and speech inference. The most impactful change was mlx-vlm’s Gemma 4 MTP and server-compatibility push, which moves MLX multimodal serving closer to cloud-style behavior. 64
DeepSpeed shipped a headline release focused less on flashy new APIs than on training correctness and multimodal scaling infrastructure. The dominant theme was making distributed training safer and more scalable, especially for multimodal ViT+LLM workloads. The most impactful change was AutoSP support for multimodal sequence parallelism. 65
Fluid Inference shipped across three repos with a strong Apple-local speech theme: Mandarin Kokoro support, TTS experimentation, diarization improvements, and text normalization fixes. The org’s release cadence reflects a tight loop between experimental conversion work in mobius and productization in FluidAudio. The most impactful change was the rapid shipping of Mandarin Kokoro ANE support into user-facing audio tooling. 66
ggml shipped an unusually dense release stream in llama.cpp, reflecting a week of rapid-fire backend, model-support, and server improvements. The dominant theme was broad hardware coverage and practical runtime safety, from Granite Speech and MiniCPM-V support to memory estimation and unsupported-architecture handling. The most impactful change was the combination of new model support with safer loading and memory-fit behavior, which keeps llama.cpp the broadest portability target in the ecosystem. 67
Google shipped releases across its edge stack, but the real story was strategic alignment around LiteRT and LiteRT-LM. The dominant theme was making on-device LLM inference a first-class runtime category with better packaging, multimodal support, and hardware-specific deployment paths. The most impactful release signal was the continued cadence in LiteRT-adjacent repos that now clearly support a dedicated edge-LLM stack. 68
Hugging Face shipped major releases in transformers and diffusers, reinforcing its role as the upstream semantic layer for the rest of the inference ecosystem. The dominant theme was new model and pipeline support paired with correctness work in multimodal, MoE, and offload paths. The most impactful change was transformers adding DeepSeek V4 and other new families, because downstream inference engines now race to match that support. 69
k2-fsa shipped a broad sherpa-onnx release spanning nearly every supported binding and app surface. The theme was multi-platform speech deployment, with new Parakeet and Nemotron support plus mobile packaging fixes. The most impactful change was the coordinated refresh itself, which keeps sherpa-onnx one of the most complete cross-platform speech inference stacks. 70
kvcache-ai shipped two releases of ktransformers centered on hybrid inference for very large MoE models. The dominant theme was DeepSeek V4 Flash support plus CPU-side low-bit expansion, showing the project’s ambition to bridge GPU and CPU execution rather than pick one. The most impactful change was native DeepSeek V4 Flash support with MXFP4 MoE and SGLang hybrid inference. 71
Luminal shipped a prerelease tied to its new YOLO example, but the broader theme was compiler/search-stack maturity and correctness. The most impactful change wasn’t the artifact itself; it was the optimizer and egglog overhaul that makes Luminal’s inference/compiler foundation more credible for broader workloads. 72
Microsoft ONNX Runtime shipped a patch release that reflects a week of attention-stack and packaging work across ONNX and ONNX Runtime. The dominant theme was adapting the ONNX ecosystem to modern transformer semantics, especially around attention, plugin distribution, and correctness. The most impactful change was the continued expansion of attention support and dispatch cleanup in ONNX Runtime’s CUDA path. 73
Mozilla AI shipped a release of llamafile focused on practical GPU usability and packaging. The dominant theme was reducing setup ambiguity on systems where backend libraries exist but don’t actually work. The most impactful change was more robust CUDA/ROCm backend detection and Windows DLL path handling. 74
NVIDIA shipped releases in both TensorRT-LLM and TensorRT-Edge-LLM, covering datacenter and Jetson deployment in the same week. The dominant theme was multimodal serving and edge deployment maturity, with TensorRT-LLM pushing model/runtime infrastructure and TensorRT-Edge-LLM improving tutorials and practical packaging. The most impactful release was TensorRT-LLM’s continued multimodal and Nemotron-oriented expansion, which keeps it central to NVIDIA’s open inference story. 75
Ollama shipped four releases in quick succession, all orbiting the same two themes: Claude/Desktop integration and deeper MLX runtime work for Gemma 4. The cadence reflects a project moving up-stack into app integration while still doing low-level Apple runtime work. The most impactful change was Gemma 4 MTP speculative decoding in the MLX runner, because it directly improves the local Apple experience while signaling where Ollama wants to compete. 76
oobabooga shipped a rapid sequence of releases around the Electron transition for text-generation-webui. The dominant theme was packaging and stabilization: moving from a browser-first app to a bundled desktop experience and then fixing the regressions that surfaced immediately. The most impactful change was the Electron rollout itself, which changes how the project is distributed and used. 77
Picovoice shipped a meaningful picoLLM release that broadens the engine beyond text into embeddings, vision, and OCR. The theme was scope expansion: turning a local LLM runtime into a more general on-device AI engine. The most impactful change was multimodal and embedding support in the core runtime. 78
Qualcomm shipped across ai-hub-models and ai-hub-apps, with the week dominated by catalog expansion, scorecard automation, and developer onboarding. The theme was making Snapdragon-targeted assets easier to benchmark, publish, and consume at scale. The most impactful change was the “similar devices” infrastructure and regenerated performance metadata, which improves portability of benchmark reporting across Snapdragon variants. 79
ROCm shipped notable releases in AITER and MIGraphX, with sherpa-onnx also appearing in the broader ROCm-adjacent stack. The dominant theme was DeepSeek V4 and MoE-heavy inference on AMD hardware, plus symbolic-shape/compiler progress in MIGraphX. The most impactful release was AITER’s release-candidate stabilization, because it directly underpins ROCm inference competitiveness in fast-moving serving stacks. 80
SGLang shipped a major release that moved the default platform baseline forward while continuing to deepen disaggregated serving and diffusion support. The dominant theme was modernization plus large-scale serving correctness. The most impactful change was the baseline move to newer CUDA and PyTorch, because it resets the default environment for users and downstream integrations. 81
Triton Inference Server shipped a release that was more about production hygiene than new features. The dominant theme was request-boundary hardening, packaging correctness, and release-cycle discipline. The most impactful change was the formal server release paired with compatibility-table refreshes that matter to downstream deployment stacks. 82
try-mirai shipped across uzu and lalamo, with the week centered on turning local runtimes into more complete products. The dominant theme was new serving surfaces and low-bit execution work, especially around the new CLI and OpenAI-compatible server mode. The most impactful change was uzu’s new CLI, which materially changes how Mirai’s runtime can be packaged and used. 83
vLLM shipped two core releases while vllm-gaudi shipped its own aligned release, making this one of the week’s most important release stories. The dominant theme was DeepSeek V4 support and stabilization across hardware backends, plus continued work in speculative decoding, KV transfer, and quantization. The most impactful change was the combination of initial DeepSeek V4 support and immediate stabilization work, which shows how quickly vLLM is turning new architectures into production targets. 84