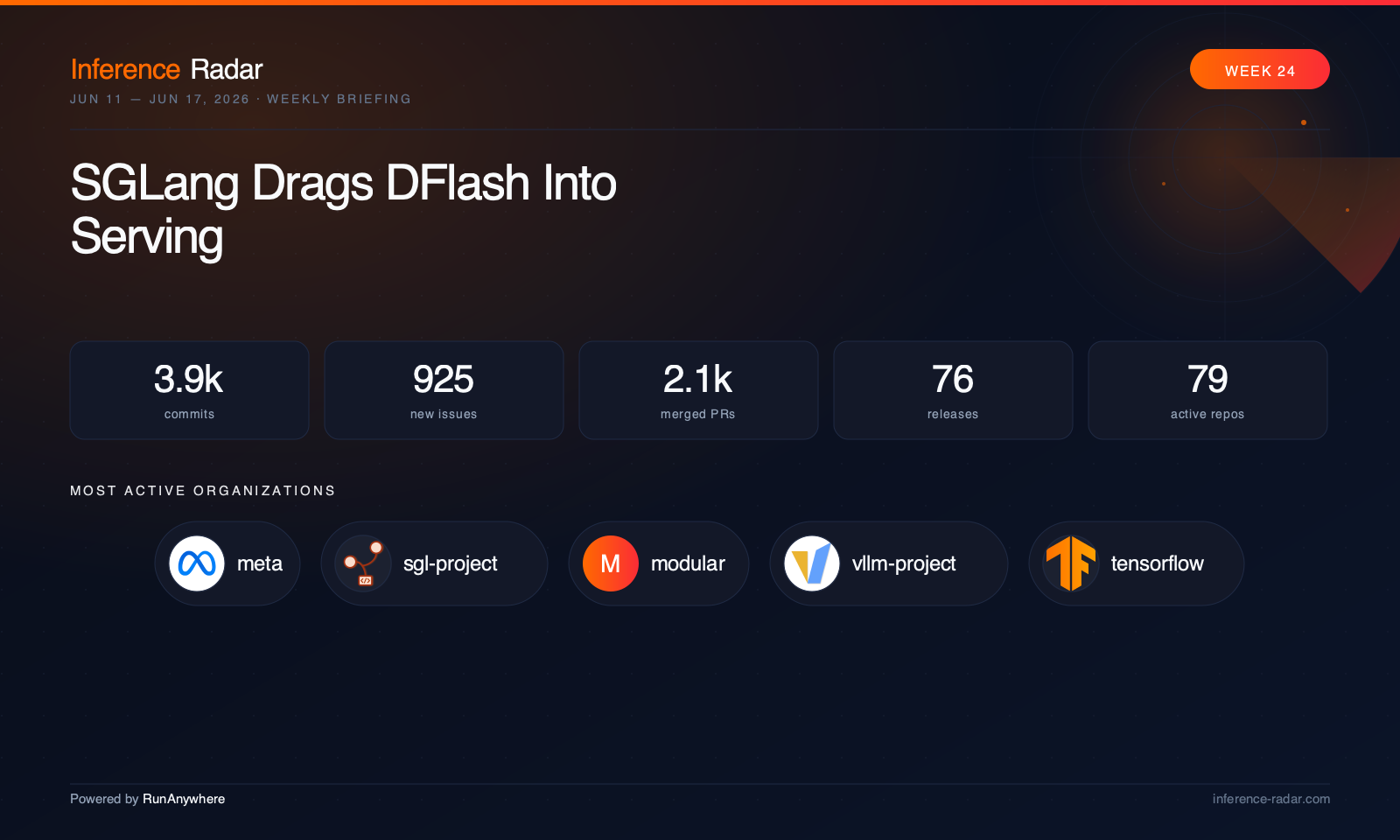

TL;DR
- vLLM moves up the stack: vLLM expanded MiniMax M3 and DeepSeek V4 work while tightening disaggregated KV transfer, parser correctness, and offload behavior.1
- SGLang leans into speculative serving: SGLang pushed DFlash and speculative decoding hard, with Blackwell-era quantization and AMD backend fixes close behind.2
- Local runtimes keep absorbing the cloud playbook: llama.cpp, Ollama, oMLX, and vllm-mlx all worked on speculative decoding, model routing, prompt/cache behavior, and OpenAI-compatible local serving.3
- Edge speech had a big week: sherpa-onnx, FluidAudio, LocalAI, Cactus, and MLX audio projects all expanded ASR, TTS, and realtime voice paths.4
- Low-bit KV is the next frontier: KVarN, KV Pareto, TurboQuant, and active engine work all point to KV-cache compression and tiered offload as the next cost lever after weight quantization arXiv.5
This Week in Inference
This was a deployment week, not a model-launch week, with no confirmed new flagship public model release in the window tracked by the supplied market briefing AI Release Tracker.6 The model pressure came from recent releases moving through engines: Google’s Gemma 4 12B kept driving local and server runtime fixes, DiffusionGemma forced projects to handle block-diffusion text generation, and MiniMax M3 became a live integration target for vLLM, SGLang, oMLX, MLX-VLM, and Dynamo vLLM.1
The week’s main technique story was memory-first inference, with KVarN reporting 2-bit KV-cache quantization using Hadamard rotation and variance normalization, KV Pareto combining KV quantization with chunked prefill and weight quantization, and engines adding more offload, cache, and prefix-reuse paths KVarN.5 The same theme appeared in code: vLLM worked on NIXL and selective KV offload, SGLang fixed HiCache and DFlash memory paths, OpenVINO refactored continuous-batching cache restore, LightLLM fixed hybrid prefix-cache defects, and Cactus optimized chunked prefill vLLM.7
Hardware news kept pointing to heterogeneity: NVIDIA’s Blackwell and Thor paths showed up in TensorRT-LLM, CUTLASS, FlashInfer, Triton, and SGLang, while ROCm pushed MI350 and gfx950 kernels through AITER and ATOM NVIDIA CUTLASS.8 Apple and mobile work also stayed active, with MLX CUDA/Linux support in Swift, Core ML conversion fixes, LiteRT WebGPU and Tensor paths, ExecuTorch WebGPU and Qualcomm work, and MNN Android packaging for new page-size requirements Apple MLX Swift.9 Industry moves pointed the same way: Nebius closed the Eigen AI acquisition for inference gains, and OpenAI model availability on AWS Bedrock showed that distribution and routing now matter as much as model weights AI Weekly.10
Top Stories
vLLM becomes a memory-hierarchy engine
vLLM’s biggest change was not one model, but the spread of memory and routing work across disaggregated serving, NIXL KV transfer, offload flushing, Mooncake cache prefixes, and MiniMax M3 support vLLM.7 The project also added a declarative streaming parser engine and stricter tool-call handling, which matters because production serving now needs correct structured output as much as raw tokens per second vLLM parser engine.11 Gaudi support tracked the same direction by updating heterogeneous HPU NIXL connector behavior for upstream V1 engine changes vllm-gaudi.12
SGLang pushes DFlash from benchmark to serving path
SGLang’s DFlash and Spec V2 work cut across fused KV helpers, Triton ops, Gemma 4 support, FlashInfer SWA indexing, and AMD fused KV materialization SGLang DFlash.2 The project paired that with speculative decoding fixes for EAGLE, MTP, multimodal chunked prefill, and draft-model KV accounting SGLang speculative fixes.13 SGLang also kept pace on Blackwell and AMD quantization, with NVFP4, MXFP8, compressed-tensors MoE, and ROCm paths all moving in the same week SGLang quantization.14
ggml keeps turning local inference into a full serving stack
llama.cpp added EAGLE3 speculative decoding, Cohere2MoE and North-Mini-Code support, router-side model management, multimodal batching fixes, and broad backend work across SYCL, Vulkan, Metal, CUDA, OpenCL, OpenVINO, WebGPU, and CPU paths llama.cpp.3 whisper.cpp added NVIDIA Parakeet support and pulled in updated ggml backend work, showing how kernel and backend changes now propagate across local LLM and speech runtimes whisper.cpp.15 Ollama then consumed new llama.cpp builds while fixing MLX support, prompt-cache behavior, and Cohere2 MoE model handling Ollama.16
Voice inference moved from demos toward product paths
sherpa-onnx added multilingual NVIDIA Nemotron streaming ASR, Qualcomm QNN Android demo plumbing, Java diacritization bindings, and an iOS ONNX Runtime refresh sherpa-onnx.4 FluidAudio shipped Parakeet Unified as streaming and offline ASR, with CoreML and ANE work flowing from research repo to production API in the same week FluidAudio.17 LocalAI, mlx-audio, mlx-vlm, Cactus, and RunanywhereAI all expanded voice, TTS, STT, or voice-agent serving paths, which makes speech one of the most active edge inference surfaces right now LocalAI.18
Compiler and kernel projects raced to match new hardware
FlashInfer added SM120 NVFP4 attention, sparse MLA, Gemma 4 head-dim support, MXFP8 MoE GEMM, and delta-rule kernels while publishing nightly builds through the week FlashInfer.19 Triton advanced sanitizer infrastructure and AMD gfx1250 TDM work, while CUTLASS added SM120 pointer-array TMA FP8 grouped GEMM and TensorRT-LLM added Blackwell and SM120 attention paths Triton.20 ROCm’s AITER and ATOM linked low-level MI350/gfx950 kernels to production LLM serving for DeepSeek, Qwen, Kimi, MiniMax, and GPT-OSS families ROCm AITER.21
Deeper Dive
Everything below is for readers who want the full picture. Feel free to scroll.
Code Changes by Category
Cloud & Datacenter Serving
vLLM worked on MiniMax M3, DeepSeek V4, disaggregated KV transfer, offload policy, streaming parser behavior, strict tool calling, DiffusionGemma, Kimi-VL CUDA graphs, and Gaudi connector parity vLLM.1 SGLang focused on DFlash, speculative decoding, Blackwell quantization, AMD paths, HiCache, disaggregated decode cleanup, and release support for new autoregressive and diffusion models SGLang.2 NVIDIA pushed TensorRT-LLM speculative decoding, SM120 attention, NVFP4 MoE, DSv4 attention, and CUTLASS GEMM support for Hopper, Blackwell, and Thor TensorRT-LLM.22 Ray Serve LLM added prefill/decode disaggregation, MoRIIO KV transfer, vLLM stack updates, and HAProxy ingress hardening Ray.23 LMDeploy added disaggregated weight updates, a Responses API endpoint, prefix-cache refactors, Qwen quantization fixes, and speculative decoding repairs LMDeploy.24 Dynamo added native vLLM backend work, dynamic LoRA, router admission control, selector sync, SGLang frontend fixes, and capacity-planner metrics Dynamo.25 LightLLM improved Qwen3.5 decode, prefix-cache correctness, profiling, and Prometheus model labels LightLLM.26
Local LLM Runtimes
llama.cpp added EAGLE3, Cohere2MoE, router model management, multimodal fixes, backend improvements, and server/tool-call polish llama.cpp.3 Ollama updated bundled llama.cpp, added Cohere Command A and North MLX support, fixed prompt-cache/context-shift behavior, and continued MLX hardening Ollama.16 LocalAI expanded realtime voice streaming, Sherpa-ONNX TTS, OmniVoice, Qwen3 TTS, Apple Silicon backend packaging, vLLM compatibility, and distributed model scheduling LocalAI.27 oMLX exposed model profiles through the models API, added MiniMax M3 support, fixed VLM/MTP routing, and tightened cache and macOS behavior oMLX.28 vllm-mlx improved reasoning extraction, multimodal chat-template kwargs, Gemma routing, SSD spill for quantized KV cache, and constrained decoding vllm-mlx.29 CTranslate2 saw issue and PR activity around Whisper word-timestamp alignment crashes on CUDA CTranslate2.30
Apple Silicon & MLX Ecosystem
Apple’s MLX core fixed Metal error propagation, LayerNorm VJP races, CUDA JIT behavior, custom Metal kernel export, quantization, autograd, and Array API semantics MLX.31 MLX-LM gated remote model-file execution behind trust controls and added sampled-token logprobs and IDs for batch generation MLX-LM.32 MLX Swift added CUDA/Linux SwiftPM support and fixed CPU-only default-device handling MLX Swift.9 MLX Swift LM added Gemma 4 speculative decoding, unified Gemma support, chunked prefill, recurrent-cache fixes, and VLM updates MLX Swift LM.33 Blaizzy’s MLX audio stack added ZONOS2, Whisper STT in Swift, Voxtral realtime streaming, Irodori TTS, and mlx-vlm OpenAI-style audio endpoints mlx-audio.34 Osaurus pinned and repinned vMLX around Gemma 4, DiffusionGemma, TurboQuant KV, runtime diagnostics, hosted inference, and proxy coverage Osaurus.35
Mobile & Edge Frameworks
ExecuTorch added CUDA multi-session mutable-state rebinding, OpenAI-compatible local serving, Qwen3.5 MoE execution, WebGPU fused SDPA and KV cache work, Qualcomm profiling and op coverage, Arm TOSA/VGF/Qwen3 VL support, and GGUF/MLX/XNNPACK improvements ExecuTorch.36 Google’s LiteRT stack advanced WebGPU TensorAPI ops, Google Tensor support, iOS CLiteRT, LiteRT-LM multimodal preprocessing, LoRA APIs, CORS serving, Android static linking, Pixel TPU benchmarks, and XNNPACK low-precision kernels LiteRT.37 Qualcomm added the GenieX Chat Android sample, Nexa SDK terminology changes, Geniex llama.cpp plugin cards, dynamic-shape Qwen3, Galaxy S26 support, and benchmark workflow updates Qualcomm AI Hub Apps.38 sherpa-onnx added Nemotron multilingual ASR, Qualcomm QNN Android demos, Java diacritization, iOS ONNX Runtime updates, and a large release asset set sherpa-onnx.4 MNN prepared Android 16KB page-size packaging, added native TopKV2 on OpenCL and Vulkan, added Wan2.1 text-to-video export and inference, and fixed Qwen2.5-Omni audio preprocessing MNN.39 Cactus added large STT streaming, Parakeet-TDT acceleration on Apple Neural Engine, Gemma 4 and LFM/Qwen multimodal fixes, and chunked prefill optimizations Cactus.40
Compilers, Runtimes & Graph Engines
OpenXLA updated LLVM, Triton, gRPC, Python toolchains, CUDA VMM allocator behavior, ROCm VMM layers, symmetric memory, NCCL peer addressing, collective command-buffer support, and GEMM fusion robustness OpenXLA.41 TensorFlow consumed the same XLA stream while adding TFLite and IFRT validation fixes, TFLite Micro quantized-kernel repairs, and TensorFlow Serving dependency rolls TensorFlow.42 Triton added sanitizer infrastructure, AMD TDM descriptor support, gfx1250 MXFP work, float64 matmul, Python compatibility fixes, and compiler correctness repairs Triton.43 TVM prepared its next release branch, moved to C++20, improved Relax frontend coverage, worked on WebGPU, TensorRT BYOC, TIRx, CUDA, RISC-V, and TVM-FFI stub generation TVM.44 ONNX shipped a new release while ONNX Runtime integrated the new opset, expanded CUDA QMoE, WebGPU/WebNN kernels, MLAS 2-bit kernels, and security hardening ONNX Runtime.45 OpenVINO improved PagedAttention, NPUW Qwen/MoE support, continuous batching, GPU/NPU runtime behavior, JavaScript image-generation APIs, and NNCF dependency hygiene OpenVINO.46 AMDMIGraphX added AMDMLSS convolution fusion, symbolic-shape infrastructure, ONNX parser coverage, pinned host-memory fallback, and portability fixes AMDMIGraphX.47
Models, Quantization & Optimization
Hugging Face Transformers added or updated MiniMax-M3-VL, Parakeet-RNNT, VibeVoice, Laguna, EUPE, GLM-5.2, PP-OCRv6, and DiffusionGemma fixes Transformers.48 Diffusers added DreamLite, PRXPixelPipeline, Cosmos3 video and audio paths, Ideogram4 LoRA support, TorchAO safetensors support, and Flux/ERNIE LoRA fixes Diffusers.49 FlashInfer added SM120 NVFP4 attention, sparse MLA, Gemma 4 head-dim support, MXFP8 MoE GEMM, delta-rule kernels, and sampler hang fixes FlashInfer.19 ROCm AITER and ATOM advanced MI350/gfx950 FP8, MXFP4, MoE, MLA, context parallelism, and model-serving integrations for DeepSeek, Qwen, Kimi, MiniMax, Mimo, and GPT-OSS ROCm ATOM.50 DeepSpeed added AutoEP for Hugging Face MoE training with presets for Mixtral, Qwen MoE, DeepSeek V2, and DeepSeek V3, plus Biren SUPA accelerator support and safer mixed-precision buffer casting DeepSpeed.51
Other Notable Changes
LiteLLM added Bedrock passthrough guardrails, Azure Responses PII handling, Snowflake Cortex routing, Voyage multimodal embeddings, Cisco AI Defense integration, and Docker image signature guidance LiteLLM.52 Open WebUI saw no merged code but heavy triage around RAG context scoping, MCP behavior, external-agent approval UX, provider requests, and contribution-process enforcement Open WebUI.53 FastChat received a security report alleging unauthenticated controller worker registration can enable SSRF and worker/model spoofing FastChat.54 RunanywhereAI merged its V2 SDK transition across Web, React Native, Swift, Android, Kotlin, and shared C++ commons, with model registry, LoRA, telemetry, and voice improvements RunanywhereAI.55 ZETIC added a large Brew AI Notes iOS sample app and fixed Qwen3Chat backup and Whisper iOS microphone-permission behavior ZETIC.56
Community Pulse
DeepSeek users kept pushing on long-context drift, context-window warnings, session handoff, external memory, and evaluation methods DeepSeek-V3.57 Ollama users reported a major MLX memory regression, GPU offload surprises, prompt-cache questions, and long-context runner timeouts Ollama.58 FlashInfer users called for invariant-oracle testing, compute-sanitizer gates, wider architecture coverage, and framework-integration checks FlashInfer.59 Open WebUI users debated message-scoped file context, RAG payload size, external-agent approval, and group model access Open WebUI.60 Triton Inference Server users reported Python backend disk leakage, TensorRT latency degradation, Python trace/span access needs, and GPU allocation protection ideas Triton Server.61 The vLLM community moved more discussion toward an external forum while GitHub issues stayed focused on MiniMax M3, FastAPI breakage, DiffusionGemma limits, and KV offload vLLM discussion.62
Community Debates
Rate limiting belongs at the frontend in Dynamo. Dynamo maintainers closed TokenBucket scheduler work because the proposals lacked end-user configuration and because request-rate limiting now points toward frontend admission and rejection paths Dynamo.63 The discussion matters because disaggregated inference stacks need a clear split between traffic policy and low-level runtime scheduling Dynamo issue.64
Ollama narrowed prompt caching instead of exposing a new public knob. A prompt-cache fix first proposed a public cache_prompt field, but maintainers pushed back on expanding the user-facing API Ollama.65 The merged path fixed the production bug by decoupling prompt caching from shift=false, which keeps hardware and cache policy out of the common API surface Ollama.65
llama.cpp maintainers kept rejecting broad or unsafe extension points. The project closed llama_batch_ext in favor of broader public batch API work, rejected a system-prefix server flag as too open-ended, and closed a tools-file server enhancement over unsafe blacklist-style execution checks llama.cpp.66 The pattern shows a project that wants server flexibility, but not at the cost of hard-to-secure APIs llama.cpp.67
ROCm rejected a DPP AllReduce fast path after measured results failed to pay off. The AITER DPP AllReduce proposal closed after MI355X testing showed neutral or slower latency and TP4 p95 regressions AITER.68 That kind of rejection is useful because the ROCm stack is optimizing for production serving wins, not kernel novelty AITER.68
vLLM closed semantic-risk parser and normalization changes as the parser engine matured. A Claude Code system-message normalization proposal raised KV-cache-hit and semantic-drift concerns, while several Gemma4 streaming and tool-call fixes closed after the new parser engine path took over vLLM.69 The next step is less ad hoc parser logic and more declarative parsing with explicit state vLLM.11
Open WebUI enforced process rules before technical review. Maintainers closed message-scoped file context, MCP nullability, provider suggestions, and group access PRs for target branch, CLA, template, title, or commit-count problems Open WebUI.70 The product debates remain active in Discussions, but the repo is making contributors fit a stricter intake path Open WebUI.60
Worth Watching
Low-bit KV cache will define the next serving cycle, with research like KVarN meeting engine work in vLLM, SGLang, LightLLM, OpenVINO, Cactus, and oMLX KVarN.5 Diffusion text models will pressure OpenAI-compatible servers because block diffusion changes generation, structured output, logprobs, and streaming assumptions vLLM DiffusionGemma.71 Blackwell and SM120 support will keep moving through FlashInfer, CUTLASS, TensorRT-LLM, Triton, SGLang, and FlashAttention before most operators see stable hardware fleets FlashInfer.19 Voice-agent serving is becoming a real workload as local stacks add ASR, VAD, TTS, audio endpoints, and latency telemetry FluidAudio.17 Security will stay close to inference operations because model files, controller registration, Python backends, passthrough providers, and web UIs now sit on exposed paths FastChat.54
Major Releases
Version numbers and release-note links live here as the reference list.
vLLM shipped vLLM v0.23.0 and vllm-gaudi v0.19.1.post1, with the core release focused on DeepSeek-V4 hardening, serving optimizations, and a large contributor cycle, while the Gaudi release patched HPU penalty-sampling behavior for the Intel Gaudi software line. The core notes also state that MiniMax M3 support was not part of that release, even though active development moved fast during the week. vLLM release notes.72
SGLang shipped v0.5.13, focused on new autoregressive model support for Nemotron 3 Ultra, Step-3.7-Flash, and Command A+, plus diffusion support for Cosmos3 and LingBot-World. The release sat alongside a week of heavy DFlash, speculative decoding, quantization, and AMD backend work..73
ggml shipped a large llama.cpp build-tag run across b9594 through b9660, with the main theme being fast follow-through on EAGLE3, Cohere2MoE, SYCL, Vulkan, CUDA, OpenCL, WASM, tool calls, and multimodal server fixes. whisper.cpp also updated version metadata after adding Parakeet support and syncing ggml backend work. Latest llama.cpp release.74
Ollama shipped v0.30.8 and v0.30.9-rc1, centered on llama.cpp refreshes, MLX hardening, Cohere2 MoE model support, prompt-cache and context-shift fixes, and editor integration drift repair. The release cadence reflects Ollama’s role as the distribution layer over llama.cpp and MLX. v0.30.8 release notes.75
Hugging Face shipped Transformers v5.12.0, v5.10.3, and v5.12.1, with the week focused on MiniMax-M3-VL, vLLM synchronization patches, PEFT bounds, tokenizer resolution, and model loading fixes. Diffusers and Candle did not publish releases, but both had active model and runtime work. Transformers v5.12.1 release notes.76
Microsoft ONNX shipped ONNX v1.22.0, with a breaking qk_matmul_output_mode value swap, operator and spec updates, and release-process cleanup. ONNX Runtime then integrated ONNX 1.22.0 and opset 27 while advancing CUDA QMoE, WebGPU/WebNN, MLAS, and hardening work. ONNX release notes.77
LiteLLM shipped a run of v1.84.7 through v1.89.0 releases, all centered on Docker image signature verification guidance using cosign. The code week was broader, with Bedrock guardrails, Azure Responses PII handling, Snowflake Cortex routing, Voyage multimodal embeddings, and Cisco AI Defense work. v1.89.0 release notes.78
FlashInfer shipped nightly-v0.6.13 builds across the week, packaging the project’s fast-moving SM120, sparse MLA, Gemma 4, MoE, and sampler reliability work into automated wheels. The most useful reference is the latest nightly from the run. Latest nightly.79
LocalAI shipped v4.4.1, v4.4.2, and v4.4.3, focused on vLLM compatibility, CrispASR and DS4 updates, realtime voice behavior, Apple Silicon backend packaging, and gallery/model fixes. The code flow also added multiple TTS backends and platform-aware meta-backend selection. v4.4.3 release notes.80
FluidAudio shipped v0.15.3, with release notes covering Kokoro/M5 routing, benchmark work, Supertonic int4 defaults, PocketTTS docs, and removal of older experimental Parakeet and Magpie items. The week’s more strategic work added Parakeet Unified streaming and offline ASR with ANE/CoreML follow-through..81
sherpa-onnx shipped v1.13.3 with a large asset set, JavaScript Supertonic3 TTS examples, Spacemit toolchain updates, React Native wrapper docs, async TTS examples, LinearResampler, and node-cpal microphone usage. The release followed major Nemotron ASR and Qualcomm QNN Android demo work..82
oMLX shipped v0.4.4rc1 and v0.4.4rc2, focused on DiffusionGemma, DeepSeek V4 oQ/MTP support, MiniMax M3, macOS compatibility, native MTP batching, and API/cache/memory-guard hardening. The RCs captured a high-speed local serving push around Apple Silicon and OpenAI-compatible APIs. v0.4.4rc2 release notes.83
Osaurus shipped 0.19.18, 0.19.19, and 0.19.20, with releases covering memory-safety status, MTP runtime status, diagnostics, UI fixes, CSV workflows, Chinese translations, image-token estimation, and Gemma 4 vMLX repins. The org also advanced hosted inference, proxy coverage, sandbox behavior, and DiffusionGemma support. 0.19.20 release notes.84
Dynamo shipped v1.2.1 and v1.3.0-minimax-m3-dev.1, with the stable patch focused on ModelExpress loading, object-storage model sources, ROCm/Python compatibility, EFA containers, and SGLang/gpt-oss correctness. The prerelease exposed early MiniMax M3 support across vLLM, SGLang, and TensorRT-LLM. v1.2.1 release notes.85
Qualcomm Nexa SDK shipped v0.3.0-alpha.1, but the provided release body had no detailed notes or assets. The week’s real signal was the GenieX/Nexa app and SDK push across Android samples, API terminology, AI Hub model metadata, and benchmark workflows..86